栏目分类
发布日期:2025-03-23 05:24 点击次数:57

文 | 谈总有理
新一年的众人科技圈,主角俨然是DeepSeek。从发布以来,DeepSeek在扫数AI产业链上激发一系列四百四病,无论是OpenAI,也曾英伟达,其彰着的畏怯似乎齐考据着DeepSeek已奇袭得手。
而DeepSeek的初步推崇也的确可圈可点,数据透露,上线5天DeepSeek日活跃用户已卓越ChatGPT,上线20天的日活达2000万东谈主次以上,已是ChatGPT的23%。现时,DeepSeek成为众人增速最快的AI哄骗。
在国际一众AI玩家不成置信的同期,国内AI规模一派“锣饱读喧天”:限度现在,阿里云、百度云、腾讯云、字节火山引擎均已郑重撑握DeepSeek;同期,百度昆仑芯、天数智芯、摩尔线程接连通知撑握DeepSeek模子。
这也美艳着众人AI竞速赛中,国产厂商终于又跨出了一步。而DeepSeek的出现,是否为僵化已久的大模子行业拆除了一些传统“吊唁”,许多至关勤勉的细节,其实还值得进一步深究。
DeepSeek出圈是“偶然性”的吗?纵不雅现时围绕DeepSeek的几大主要争议,似乎每少许都指向解除个问题:DeepSeek是否真的收尾了大模子的时间浮松。早在DeepSeek公布其模子试验成本仅为行业1/10时,就有声息质疑,DeepSeek是通过大幅缩减模子参数限度,或依赖母公司幻方早期囤积的低价算力收尾的。
从某种角度来看,这些质疑有迹可循。
一方面,DeepSeek在缩减模子参数限度方面的“激进”有目共睹,另外一方面,DeepSeek背后的幻方如实有一定的算力储存。据悉,幻方是BAT以外惟一能够储备万张A100芯片的公司,有报谈在2023年就曾公布过国内囤积卓越1万枚GPU的企业不卓越5家。
幻方即是其中之一。
但值得一提的是,无论是模子参数限度的缩减,也曾算力篡改争议都无法辩白DeepSeek“小力出名胜”吩咐的本体意思意思。最初,DeepSeek-R1在参数目仅为1.5亿(1.5B)的情况下,在数学基准测试中以79.8%的得手率超越GPT-4等大模子。
其次,轻量化模子自然在推聪慧商与性能方面推崇更出彩,试验和初始成本也更低。据悉,DeepSeek以仅需1/50的价钱提供了GPT-4访佛的性能,在中袖珍企业和个东谈主开拓者中劫夺了一定的市阵势位。
至于幻方对DeepSeek的加成,与其说是一场本钱的偶然游戏,不如说是国产大模子成长的势必散伙。值得提防的是,幻方量化算是国内第一批闯入大模子赛谈的企业,早在2017年,幻方就声称要收尾投资战略全面AI化。
2019年,幻方量化成立AI公司,其自研的深度学习试验平台“萤火一号”总投资近2亿元,搭载了1100块GPU;两年后,“萤火二号”的参加增多到10亿元,搭载了约1万张英伟达A100显卡。
2023年11月,DeepSeek 的首个开源模子 DeepSeek-Coder发布。也即是说,这个引起国际科技巨头集体破防的DeepSeek不是通宵之间的产物,而是国产AI厂商在大模子布局中旦夕要走的一步。
不成辩白,现时国内已具备栽培“DeepSeek ”的客不雅条目。公开而已透露,一个全面的东谈主工智能体系正在各方本钱的追捧下出身,国内东谈主工智能筹划企业卓越4500家,中枢产业限度接近6000亿元东谈主民币。
芯片、算法、数据、平台、哄骗……我国以大模子为代表的东谈主工智能擢升率达16.4%。
自然,DeepSeek的时间旅途依赖风险永远存在,这也让DeepSeek的出圈多了一点偶然,尤其“数据蒸馏时间”不竭遭逢重重质疑。事实上,DeepSeek并非第一个使用数据蒸馏的大模子,“过度蒸馏”致使是现时东谈主工智能赛谈的一大矛盾。
来自中科院、北大等多家机构就曾指出,除了豆包、Claude、Gemini以外,大部分开/闭源LLM蒸馏程渡过高。而过度依赖蒸馏可能会导致基础接头的停滞,并裁汰模子之间的各种性。上海交通大学也有素质表示,蒸馏时间无法处分数学推理中的根人道挑战。
一言以蔽之,这些都在反逼DeepSeeK乃至扫数国产大模子赛谈接续自我考据,偶然,国内还会出身第二个“DeepSeek”,从现实的角度来看,DeepSeek得手的势必远广博于偶然。
“开源期间”要莅最后吗?值得提防的是,比拟于时间之争,DeepSeek也再度激发了众人科技圈对开源、闭源的强烈论证。Meta首席科学家杨立昆还在酬酢平台上表示,这不是中国在追逐好意思国,而是开源在追逐闭源。
谈及开源模子,还要回首到2023年Meta的一场源代码泄露风云。彼时,Meta见机而作发布了LLama 2开源可商用版块,顿时在大模子赛谈掀翻开源怒潮,国内诸如悟谈、百川智能、阿里云纷纷进入开源大模子规模。
字据Kimi chat统计,2024年全年开源大模子品牌卓越10个。2025年开年不及两个月,除了大火的DeepSeeK以外,参与开源者罪过昭着。
据悉,1月15日,MiniMax开源了两个模子。一个是基础话语大模子MiniMax - Text - 01,另一个是视觉多模态大模子MiniMax - VL - 01;同期,NVIDIA也开源了我方的宇宙模子,差别有三个型号:NVIDIA Cosmos的Nano、Super和Ultra;1月16日,阿里云通义也开源了一个数学推理历程奖励模子,尺寸为7B。
从2023年到2025年,无数AI东谈主才争论不停后,大模子的“开源期间”终于要来了吗?
不错信托的少许是,比起闭源模式,开源模子能在短时期内凭借其敞开性获取大都关怀。公开而已透露,往日在“LLama 2”发布之初,其在Hugging Face检索模子就有超6000个散伙。百川智能方面则透露,旗下两款开源大模子在往日9月份的下载量就卓越500万。
事实上,DeepSeek能快速走红与其开源模式分不开联系。2月统计透露,现时接入DeepSeek系列模子的企业不计其数,云厂商、芯片厂商、哄骗端企业齐来凑了把侵扰。在AI需求鼎沸确现时,大模子开源似乎更能促进AI生态化。
但大模子赛谈开源与否,其实还有待商榷。
Mistral AI、xAI诚然都是开源的撑握者,但它们的旗舰模子现在都是禁闭的。国内大部分厂商基本亦然一手闭源,一手开源,典型的例子如阿里云、百川智能,致使李彦宏一度是闭源模式的诚笃拥趸。
原因并不难揣度。
一方面,在众人科技规模里开源AI公司都不受本钱原宥,反而是闭源AI企业在融资方面更有上风。数据统计透露,从2020年以来,众人闭源 AI 规模初创公司已完成 375 亿好意思元融资,而开源类型的 AI 公司仅获 149 亿好意思元融资。
这对用钱如活水的AI企业而言,其中的差距不是一星半点。
另外一方面,开源AI的界说在这两年愈发复杂。2024年10月份,众人敞开源代码促进会发布对于“开源AI界说”1.0版块,新界说透露,AI大模子若要被视为开源有三个重心:第一,试验数据透明性;第二,完竣代码;第三,模子参数。
基于这一界说,DeepSeek就被质疑不算果真意思意思上的开源,仅仅为了相投短期声威。而在众人范围内,《Nature》的一篇报谈也指出,不少科技巨头声称他们的AI模子是开源的,现实上并不十足透明。
前几日,受到“打击”的奥尔特曼初度正面承认OpenAI的闭源“是一个诞妄”,偶然,赶着DeepSeek的热度,一场AI界的“涎水大戏”又要拉开序幕。
大限度的算力参加行将“暂停”?这段时期,不少千里迷囤积算力的AI企业因DeepSeek的横空出世遭到冷嘲热讽,英伟达这类算力供应商还在股价上跌了一个巨大的跟头。坦直来说,DeepSeeK在某些方面的确带来了新的浮松,尤其在“控制吊唁”上,缓解了一部分惊悸。
但众人大模子赛谈的算力需求依旧不成苛刻,致使DeepSeeK本身都未必能暂停算力参加。
需要提防的是,DeepSeek现在仅撑握笔墨问答、读图、读文档等功能,还未触及图片、音频和视频生陋习模。即便这么,其劳动器还困在崩溃的角落,而一朝念念要改变格式,算力需求则会呈爆炸式增长,视频生成类模子与话语模子之间的算力需求差距甚大。
公开数据透露,OpenAI的Sora视频生成大模子试验和推理所需要的算力需求差别达到了GPT-4的4.5倍和近400倍。从话语到视频之间的跨度尚且如斯之大,跟着各种超等算力场景的出身,算力树立的必要性只增不减。
数据透露,2010年至2023年间,AI算力需求翻了数十万倍,远超摩尔定律的增长速率。进入2025年,OpenAI发布了首个AI Agent居品Operator,大有要引爆超等算力场景的趋势,这才是联系算力树立是否接续的要津。
据悉,现时大模子发展界说整个分为五个发展阶段:L1 话语智商、L2 逻辑智商、L3 使用器具的智商、L4 自我学习智商、L5 探究科学律例。而Agent位于L3 使用器具智商,同期正在开启对L4的自我学习智商的探索。
字据Gartner预测,到2028年,众人将有15%的泛泛责任有谋略瞻望将通过Agentic AI完成。淌若大模子赛谈按照预备意象地一谈决骤,从L1到L5,众人各大AI企业对算力的树立愈加不会苛刻。
到L3阶段,算力需求概况会是若干?
巴莱克银行在2024年10月份的一则叙述中预测过,到2026年,假如消耗者东谈主工智能哄骗能够浮松10亿日活跃用户,况兼Agent在企业业务中有卓越5%的浸透率,则需要至少142B ExaFLOPs(约150,000,000,000,000 P)的AI算力生成五千万亿个token。
即便超等哄骗阶段的到来还遥不成及,在现在大模子赛谈加快淘汰的强烈战场上,也莫得一家企业应许过期一步。微软、谷歌、亚马逊、Meta、字节越过、阿里、腾讯、百度……这些海表里的AI巨头或许会接续用钱赌畴昔。
另外,DeepSeek最为东谈主称谈的莫过于绕开了“芯片大关”。
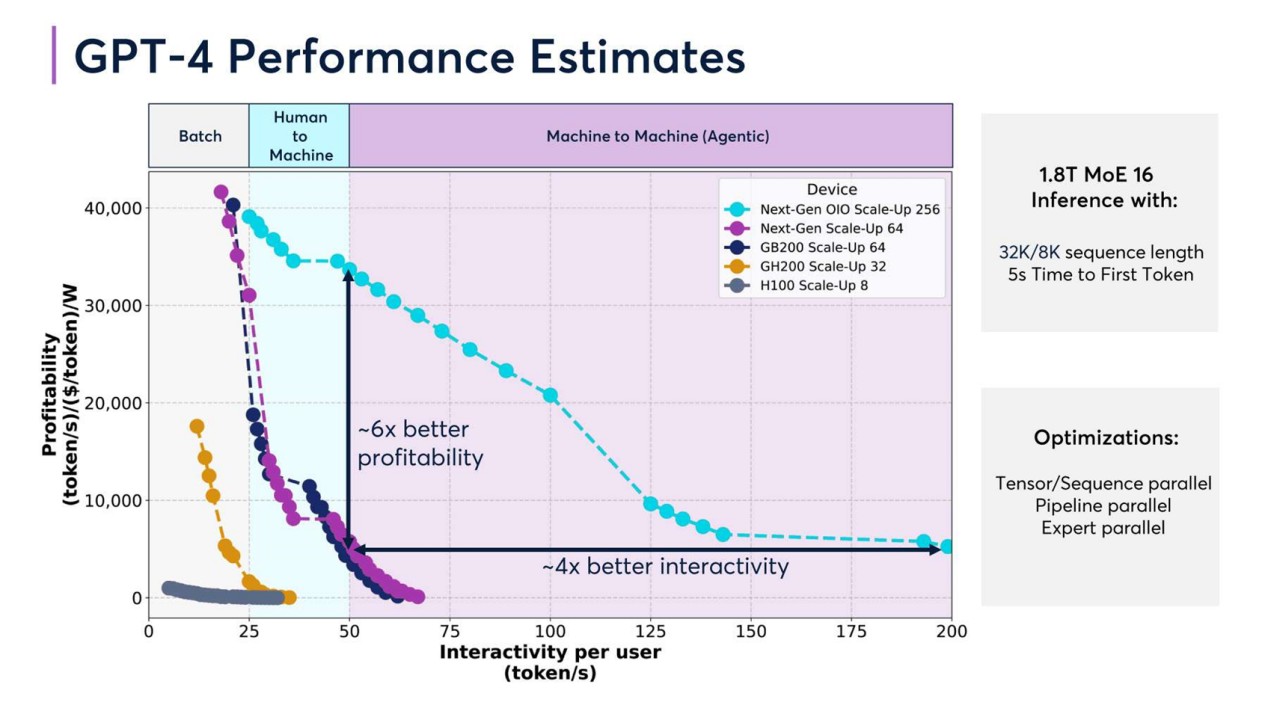
但是,当作算力产业的基石,研讨参加下,优质的算力基础步调相通会提供更高的算力恶果与买卖陈述。《2025年算力产业十大趋势》中提到过,以GPT-4为例,不同硬件配置下其性能会发生权贵各别。对比H100和GB200等不同硬件配置驱动GPT-4的性能,选拔GB200 Scale-Up 64配置的盈利智商是H100 Scale-Up 8配置的6倍。
DeepSeek一问三崩的劳动器,偶然表示着大模子赛谈的“追芯”游戏在算力角逐身手中迟迟未能收尾。据悉,2025年,英伟达下一代GPU GB300可能会出现多个要津硬件规格变化,而国内的AI芯片国产化进度也星夜兼程。
各种迹象透露,缺乏的算力树立一时半会无法住手,反而更卷了。
【钛度号作家先容:谈总有理,曾用名歪谈谈,互联网与科技圈新媒体。本文为原创著述,报复未保留作家筹划信息的任何格式的转载。】