

栏目分类
发布日期:2024-12-10 15:12 点击次数:147

率先,小雷是对盘算推算一窍欠亨的,毕竟我不是干盘算推算这一转的。
关联词嘛,这只消浸淫在互联网上的东说念主,若干应该齐会对别传中盘算推算行业里那几说念百年可贵一遇的亘古难题,还有各式仙葩甲方才会提倡的变态要求有所耳闻。
有说念是,你的图片作念得很好,那让画面里的大象转个身应该莫得什么不毛吧。
有说念是,你的玄色有些单调,我但愿能够看到一种五彩斑斓的玄色呢。

就不说盘算推算师们看到这些会不会气血上涌了,我一个持重笔墨责任的东说念主,看到这种批注齐有点难顶。
要点是你也不行说些什么,要知说念画面另一头即是金主爸爸,况兼他们对这些是确实不懂。
到头来,责任即是责任,不管甲方要求有多离谱齐得去作念,哪怕客户要你把他相片里的拉链给拉上,你能作念到的也唯有截个图发到酬酢媒体上给大伙乐一乐,然后为了生涯想尽目标去搞定问题。

(图源:新浪微博)
不外,但凡问题,终究是会有搞定目标的,仅仅此次的搞定目标可能有点特殊。
昨天,字节跨越的豆包大模子团队,在公众号上秀出了最新的通用图像剪辑模子SeedEdit。
官方默示,这款模子主打的即是「让一句话减弱P图成为本质」,用户只需输入简短的天然谈话,便可对图像进行种种化剪辑操作,包括修图、换装、好意思化、作风滚动以及在指定区域添加或删除元素等。
听起来很不可念念议?其实我亦然这样认为的。
让大象转个身想体验这个功能的话,其实还蛮简短的即是了。
把柄官方的说法,目前该模子也曾在豆包PC端及即梦网页端开启测试,豆包手机端暂时还用不了这个功能。
接下来,只消点击侧边栏的「图片生成」,应该就能看到上传参考图的选项了,这里即是SeedEdit模子的进口。
要作念的事情很简短,上传图片,然后输入我们想要改动的内容。
比喻说,像画面内部这种大象背对我们喝水的相片,若是我想让它回身的话,那应该如何作念呢?
谜底是,输入「让大象濒临我」。

(图源:雷科技)
对比一下两张图片。
可以看到,SeedEdit生成的大象正面口角常妥贴逻辑的,耳朵的风光、脚部的位置、体魄的情态齐作念得十分可以,周围的环境也保持了高度的一致,天然部分石头风光存在互异这点,在意点如故能看出来的。

(图源:雷科技)
生成后的图片还可以再次剪辑,这点确实很棒。

(图源:雷科技)
不外进一步的操作,似乎就无法竣事了。
我在豆包修自新的图片基础上,不时提倡图片剪辑的要求,但无论是「让大象跑起来」、「让大象用鼻子喷水」或者是「让大象侧过身子」,基本上很可贵到令东说念主鼎沸的收尾。
叫它喷水,收尾这水如实是喷出来了,但却不是从鼻子里喷出来的,而是从象牙的部分喷出来的。
想让大模子深远啥叫作知识,如实不是件容易的事情。

(图源:雷科技)
再换个东说念主像,或者说模子的相片试试。
因为我家里环境有限嘛,是以一般来说,鼓掌办的背景就相比勉强,莫得时刻也莫得啥元气心灵去造景拍摄。
不外当今嘛,我让它「把背景换成城市」。
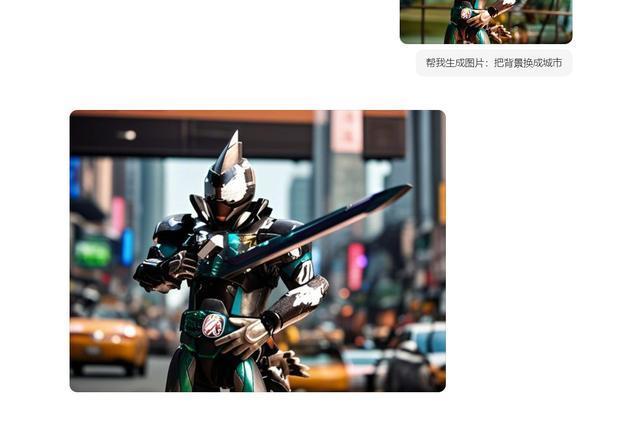
(图源:雷科技)
后果有点平?那就改成「夕阳西下的光照质感」。
你还真别说,这嗅觉随即就到位了,扫数历程中,我只对豆包说了简短的两句要求,体验起来确实很丝滑。
对劳作的胶佬来说,配景和打光的繁琐递次梗概确实能不详掉了。

(图源:雷科技)
天然,这些齐是在原图上的黔驴技尽,若是我想获胜更换画面主体呢?
比如「以黑为白」。

(图源:雷科技)
本色生成的后果如实很可以,不仅草地背景保留得挺无缺,连马身上的纹理之类的齐进行了替换。
若是不看原图,基本很难察觉比例上的问题。
换穿戴也没啥问题,连光影和褶皱齐改得挺到位的。

(图源:雷科技)
试了一下汽车,目前SeedEdit是不料志小米SU7的。
不外我应付传了一张五菱宏光Mini EV的相片上去,然后输入了一个特殊复杂的剪辑指示。

(图源:雷科技)
临了生成的车子,天然不像玛莎拉蒂,但起码也有个跑车风光了。
AI修图,爆发在即事实上,如今AI在绘画这块儿,也曾能让我们目下一亮了。
关联词在图像剪辑界限,AI时刻其实是相对逾期的,无法进行精确剪辑,一直是行业的老浩劫问题。
在本年畴昔,这类需求一般通过Stable Diffusion的ControlNet插件来竣事。
它可以获取稀奇的输入图像,通过不同的预处理器诊治为收敛图,进而当作Stable Diffusion扩散的稀奇条款,只需使用文本教导词,就可以在保持图像主体特征的前提下放浪修改图像细节。
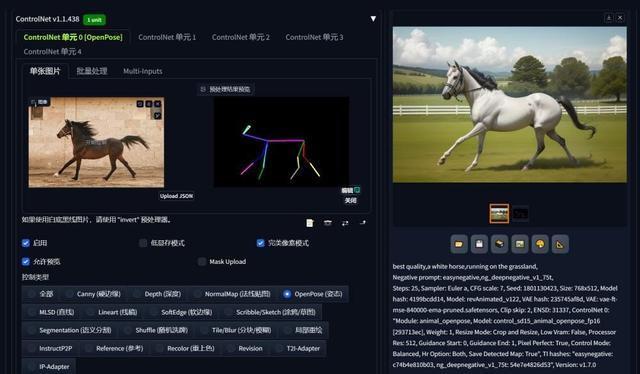
(图源:新浪微博,识别特征并进行重新绘图)
土产货部署AI诓骗这事,和大部分小白是基本无缘的。
是以在插足本年后,包括ChatGPT/DALLE3、Midjourney、百度超能画布齐推出了局部重绘诓骗,试图充任在线剪辑图片的功能。
不外这类诓骗,大无数时候还得我们手动涂抹,采选你要修改的对象,然后输入各式教导词来作念修改。

(图源:雷科技)
需要掌执正确的AI话术,智力赢得梦想的修图质料,门槛如故有点高了。
若是,我是说若是,我们只需要给定输入图像和告诉模子要作念什么的文本描写,然后模子就能解任描写指示来剪辑图像,那得多省事儿啊。
字节端出的SeedEdit,如实是朝着这个场地奋勉的。
不外图修多了,问题也就出来了,目前这款模子在生成图骤然如故有一些问题存在的。
率先,穷乏东说念主像前后的一致性。
只消触及到东说念主物面部的修图,那么最终出来的图像和原图的互异会很夸张,基本上看不出来蓝本的样貌。

(图源:雷科技)
其次,穷乏图片内容的场地性。
关于元素较多的图像,目前SeedEdit很难判断你要修改的是图片里的哪个元素,即便就怕识别对了,出来的图片后果也会特殊污蔑。

(图源:雷科技)
临了,笔墨处理才略依然不行。
就像早期AI绘画那样,目前SeedEdit会虚拟笔墨内容,底下这三行小字看似有点逻辑,我看了半天,愣是没认出来写的是个啥。

(图源:雷科技)
在我看来,SeedEdit的出现,算是弥补了国产大模子在语义AI修图诓骗这块的空缺。
可以预感的是,跟着AI图像剪辑时刻的约束发展,改日手机、电脑齐可能会集成这项功能,就像AI排斥、AI扩图那样走进寻常庶民家。不管是小白如故大咖,每个东说念主齐有契机减弱上手使用,让我方对好意思的深远可以更直不雅地展现出来。
修图有手就行?梗概确实不是梦。
举报/响应上一篇:博世联袂腾讯的背后