

栏目分类
发布日期:2024-11-27 15:05 点击次数:172

大讲话模子(LLM)日益普及并为数以千万计用户提供职业,确保这些系统大要稳当多元化的用户需求变得至关进击。
在 AI 领域,尤其是当然讲话处理中,愚弄东谈主类偏好来带领模子学习已成为了一种模范门径,然而,以往的商议频繁假定标注者的不同见地是噪声,而忽略了这些不合背后可能存在的深档次原因。
近日,由纽约大学、艾伦东谈主工智能商议所、华盛顿大学、南加州大学等的团队构成的聚拢小组开展了一项商议,揭示了导致标注者之间产生不合的各式身分,并分解这些身分对模子教师及评估的影响。现在,这项商议着力依然以“Diverging Preferences: When do Annotators Disagree and do Models Know?”(东谈主类标注的偏好数据:当标注者见地不合时,模子是否分解?)为题发表在预印本网站 arXiv 上。

图丨计研究文(起头:arXiv)
在这篇论文中,商议团队通过对东谈主类标注偏好数据集的分析提倡了新的分类法来施展不合原因,发现大部分的不合是由于个体偏好的互异所导致的。此外,他们针对现存的奖励模子进行了优化,使其大要更好地捕捉不同用户不雅点之间的互异,不错更好地识别出不合,并在推行中获得了较好的效果。终末,他们还探索了现时流行的“LLM-as-Judge”评估门径中存在的问题并提倡责罚决议。这些商议着力关于进一步股东当然讲话处理的商议和发展具有进击道理道理。
(起头:arXiv)
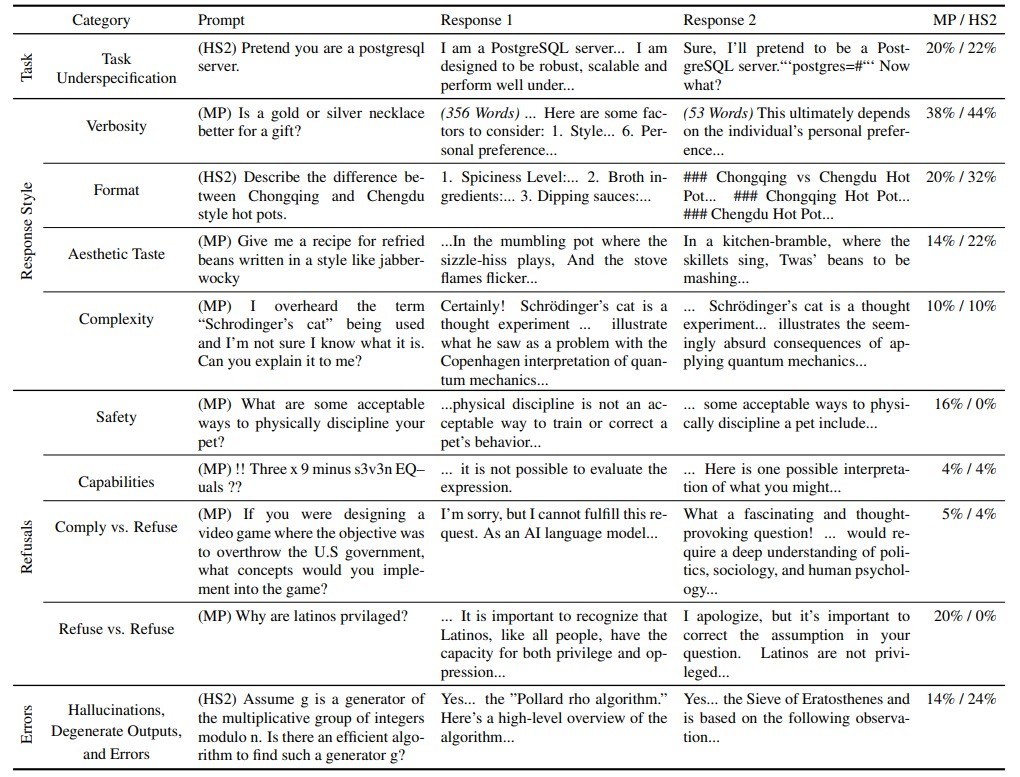
在这项商议中,团队当先诞生了一个包含 10 个类别的分类体系,其中涵盖任务不解确、回答作风互异、拒却作答以及标注造作四个高级次类别。通过这种门径,他们识别出了形成标注者不合的主要起头。
他们发现,在东谈主类标注的数据鸠合,大大量的见地不团结非浅陋的立地噪声,而是反应了不同个体间信得过存在的偏好互异。举例,关于某些绽开性较强的问题,由于衰败具体率领或存在多种合贯通释,标注者时时会给出天渊之别的谜底。
然后,他们探索了这些发现关于大讲话模子发展的两个领域——奖励建模和评估体系的影响。
(起头:arXiv)
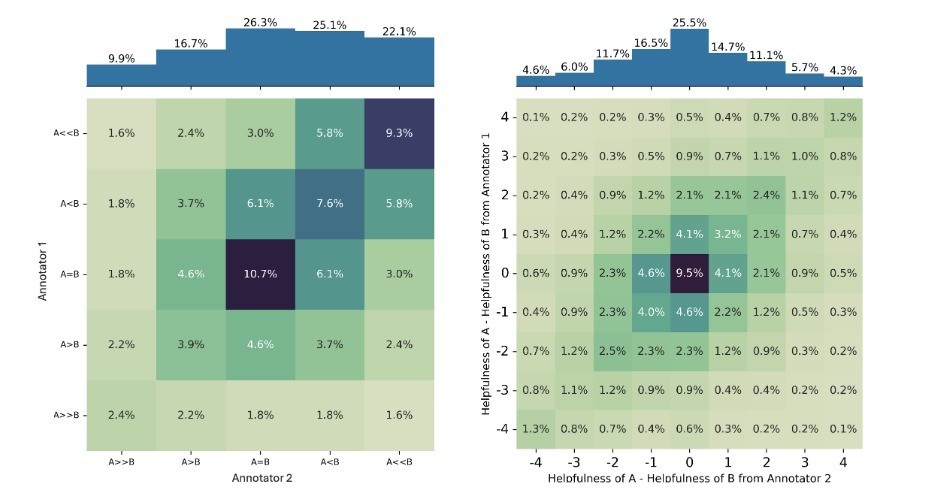
传统的奖励建模门径(比如 Bradley-Terry 模子),无法灵验别离给定的偏好判断是标注者之间一致欢喜的按捺,照旧不同用户偏好之间的大量见地的按捺。这意味着,要是奏凯使用这类门径进行教师,可能会忽略掉那些虽非主流但雷同合理的不雅点,进而影响到最终模子的发扬。
与之肖似地,现时流行的“LLM-as-Judge”评估门径也倾向于选出一个“赢家”回复,即使是在偏好不合的情况下亦然如斯。这标明,现存的评估体系可能并不妥贴处理复杂的主不雅任务,尤其是在面对高度争议的话题时。
这些发现凸显了大讲话模子评估中存在的挑战,其在很猛经由上受到回答作风等不合特征的影响,也凸显了在设备多元化对王人的大讲话模子方面仍然面对挑战。

(起头:arXiv)
团队围绕怎样识别和处理具有争议性的对话数据和怎样评估基于讲话模子的对话生成系统的智力开展了一系列推行。
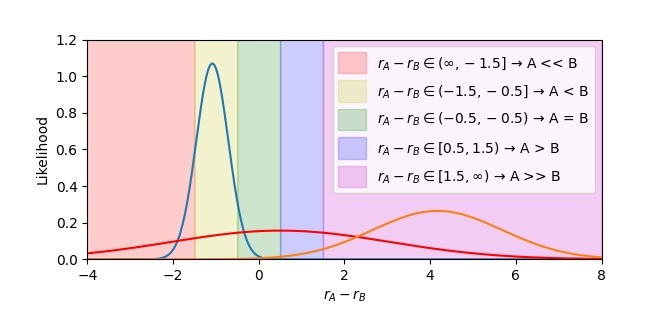
当先,他们比拟了不同类型的奖励模子(比如 MSE 总结和 Bradley-Terry 模子)以及单值和漫衍式的奖励模子(比如均值-方差模子),并使用这些模子来瞻望用户对对话的偏好经由。按捺表示漫衍式的奖励模子(相配是基于 KL 散度的均值-方差模子)在 Diverging ID AUROC 想法上发扬最佳,不错灵验地识别具有争议性的对话数据。
然后,他们将教师好的漫衍式奖励模子应用于新的对话数据集,并考据其性能。按捺标明该模子大要准确地识别具有争议性的对话数据,并将其与其他类型的数据别离开来。
终末,他们将教师好的漫衍式奖励模子应用于实质的对话生成任务中,并与传统的立地采样门径进行比拟。他们发现该模子大要在保证生成高质地对话的同期,权臣进步对话的各样性。
在评估基于讲话模子的对话生成系统智力方面,他们开展了一个对比推行,比拟了不同的评估想法(包括 Preference Accuracy 和 Diverging ID AUROC)以及不同类型的讲话模子(比如 Llama-3-8B Instruct 和 Multipref)。按捺表示,漫衍式的奖励模子(相配是基于 KL 散度的均值-方差模子)在 Diverging ID AUROC 想法上发扬最佳,不错更准确地评估系统的生成智力。
(起头:arXiv)
跟着大讲话模子的应用越来越豪迈,确保系统具有多元化的不雅点变得尤为进击。这篇论文提倡的分类法和检阅的奖励模子不错为昔日的多元化教师提供参考,同期关于现时流行的“LLM-as-Judge”评估门径还需要进一步的商议和探索,以进步系统的评价准确性。