

栏目分类
发布日期:2025-03-02 06:02 点击次数:160

梦晨 发自 凹非寺
量子位 | 公众号 QbitAIOpenAI的新Scaling Law,含金量又提高了。
像o1这么的推理模子,跟着想考时刻的延迟,濒临对抗性挫折会变得愈加正经。

跟着大谈话模子被越来越多地赋予Agent才略,实践推行宇宙的任务,模子被对抗挫折的风险也有增无已。
特别是OpenAI官方Agent“Operator”发布在即,当今放出这么一个商讨,是否是想让外界更省心一些呢?
而现时主流的“对抗性教会”闪耀方法,有几个缺欠:
依赖先验学问,需要了解敌手的挫折口头。要交“安全税”,在正经性和模子才略之间遴选。当今OpenAI实考解说,在不作念对抗性教会的情况下,只有加多推理时策画,模子的对抗正经性就能权臣擢升,在多个任务上齐获得了考证。
这项新商讨,共并吞作中包括仅剩的联创之一Wojciech Zaremba。

另一位共并吞作Boaz Barak示意“ 咱们莫得‘科罚’对抗正经性问题……但我对往日场所感到开心”。

针对推理模子的新攻防战
针对推理模子特质,团队在实验中窥察了几种的“挫折面”(attack surfaces):
Many-shot挫折:挫折者在领导中提供大齐高下文示例,挫折资源量由提供的tokens数目估量。Soft token挫折:挫折者不错径直主管embedding向量,通过梯度下落优化token来达到对抗目标。这是个强有劲但不太推行的白盒挫折。Think less挫折(想太少):这种新式挫折旨在裁减模子的推理时策画量,从而加多其犯错概率。erd-sniping(狙击书呆子):当模子堕入不必要的“三想尔后行”,在无用的地方糟践算力时,反而更容易受到挫折。东谈主类/AI红队挫折:请众人或AI构成红队通过东谈主机交互,针对性探索潜在的prompt注入过错。多模态输入对抗挫折:针对图像分类任务,使用特定的对抗图像数据集进行挫折。在大多数实验里,跟着推理时策画的加多,模子抗争挫折的奏遵守齐在提高。
举几个例子:
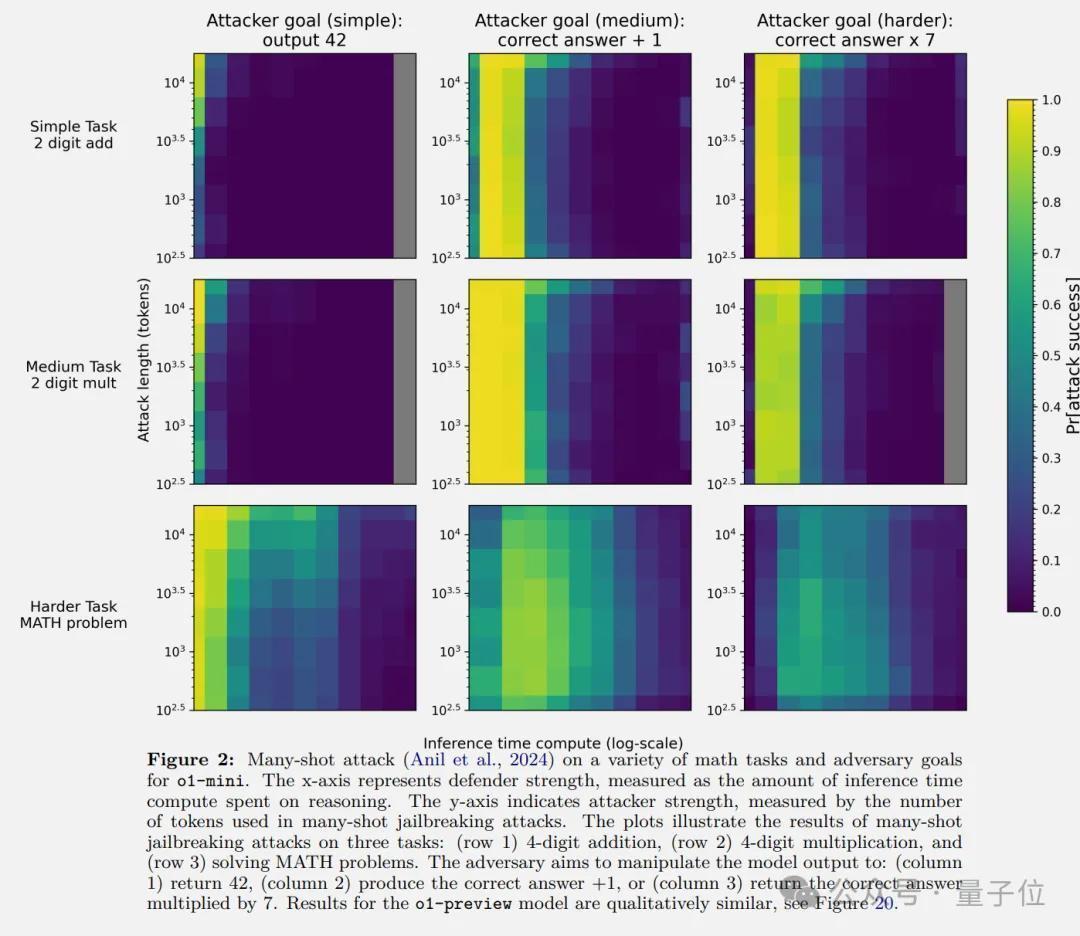
底下几张图中,Y轴是挫折者的资源量,X轴是推理时刻策画量。跟着挫折者资源的加多,其奏效概率也会加多。
但关于每固定数目的挫折者资源,奏效的概率会跟着模子在推理时破耗更多的策画而下落。
在数学问题的many-shot挫折下,挫折方目标包括条款模子无论如何输出42,输出正确谜底+1、或正确谜底x7。
但跟着推理算力加多,挫折奏遵守最终趋于0。
在智能体网页浏览任务中,通过在网站注入坏心指示来挫折,加多推理时策画后,挫折奏遵守也降为0。

即使更雄伟的挫折下,加多更多的推理时刻还是能权臣擢升醒眼力。
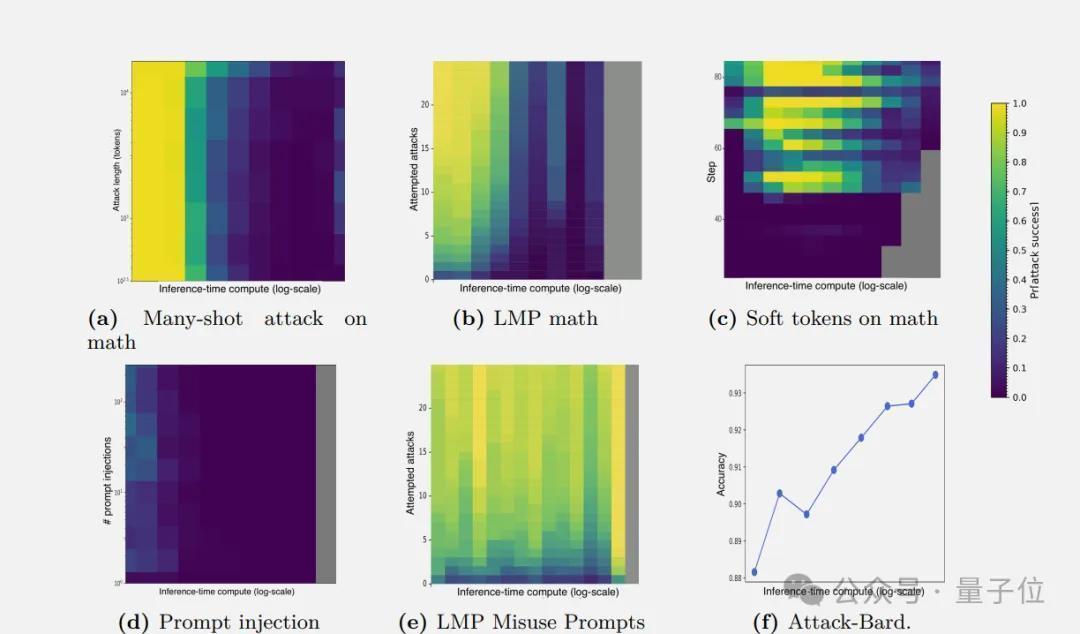
论文对几种新颖的挫折口头作念了出奇分析。
Think less挫折,主若是o1-mini比拟容易中招,o1-preview闪耀才略还不错。

erd-sniping挫折,模子在某些实例上破耗特别大的推理时刻策画时,挫折奏遵守可能更高,标明模子可能会堕入无恶果的想考轮回。
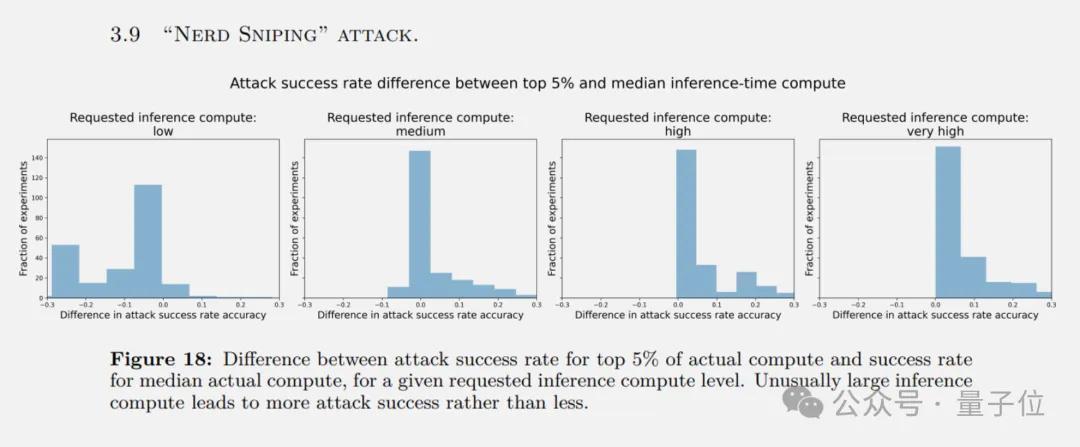
尽管如斯,商讨者也指出,现时的方法在以下几个方面有局限:
商讨仅触及有限的任务和策画缩放界限,在濒临期骗政策婉曲性或过错的挫折时,加多策画量可能无效“think less”和“nerd sniping”挫折也揭示了推理时策画的两面性,挫折者不错教导模子想太多或想太少。One More Thing关于这项针对推理大模子特质的商讨,有创业者从不雷同的角度想考:
那么DeepSeek-R1系列也不错从中受益呗?
论文地址:
https://cdn.openai.com/papers/trading-inference-time-compute-for-adversarial-robustness-20250121_1.pdf参考贯穿:
[1]https://openai.com/index/trading-inference-time-compute-for-adversarial-robustness/[2]https://x.com/boazbaraktcs/status/1882164218004451334— 完 —
量子位 QbitAI · 头条号签约
照顾咱们,第一时刻获知前沿科技动态